Kodiranje ASCII. Tabela kodiranja ASCII
Pod informacije o kodiranju v računalniku se razume proces preoblikovanja v obliko, ki omogoča organiziranje bolj priročnega prenosa, shranjevanja ali avtomatske obdelave teh podatkov. V ta namen se uporabljajo različne tabele. Kodiranje ASCII je prvi sistem, razvit v Združenih državah Amerike za delo z besedilom v angleškem jeziku, ki je bil nato razširjen po vsem svetu. Njegov opis, lastnosti, lastnosti in nadaljnja uporaba izdelka so predstavljeni spodaj.
Prikaz in shranjevanje informacij v računalniku
Simboli na računalniškem monitorju ali mobilnem digitalnem pripomočku so oblikovani na podlagi nizov vektorskih oblik različnih znakov in kod, ki omogočajo, da se med njimi najde znak, ki ga je treba vstaviti na pravo mesto. Gre za zaporedje bitov. Tako mora vsak simbol nedvoumno ustrezati nizu ničel in tistih, ki stojijo v določenem, unikatnem vrstnem redu.
Ad
Kako se je vse začelo
V zgodovini so bili prvi računalniki angleško govoreči. Za kodiranje podatkov o znakih v njih je bilo dovolj uporabiti samo 7 bitov pomnilnika, za ta namen pa je bil dodeljen 1 bajt, sestavljen iz 8 bitov. Računalnik je v tem primeru razumel 128 znakov. Ti znaki so vključevali angleško abecedo z ločili, številkami in nekaterimi posebnih znakov. Angleško sedem-bitno kodiranje z ustrezno tabelo (kodno stran), razvito leta 1963, je dobilo ime American Standard Code za izmenjavo informacij. Običajno je bila za svojo oznako uporabljena kratica “ASCII Coding” in se še vedno uporablja.
Ad
Prehod na večjezičnost
Sčasoma so se računalniki začeli pogosto uporabljati v državah, ki niso angleško govoreče. V zvezi s tem obstaja potreba po kodiranju, ki omogoča uporabo nacionalnih jezikov. Odločeno je bilo, da se kolo ne izumlja in ASCII kot osnovo. Tabela kodiranja v novi izdaji se je znatno razširila. Z uporabo 8. bita lahko prevedemo 256 znakov v računalniški jezik.
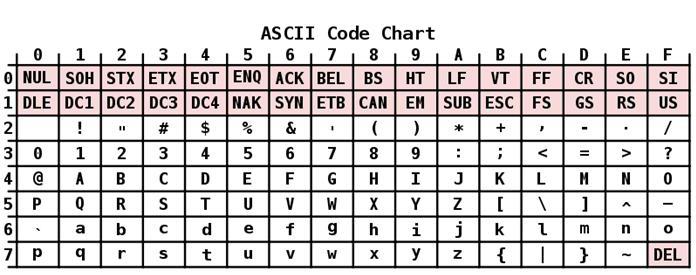
Opis
Kodiranje ASCII ima tabelo, ki je razdeljena na dva dela. Splošno sprejet mednarodni standard velja samo za prvo polovico. Vključuje:
- Znaki z zaporednimi številkami od 0 do 31, kodirani z zaporedji od 00000000 do 00011111. Rezervirani so za kontrolne znake, ki nadzorujejo prikazovanje besedila na zaslonu ali tiskalniku, pisku itd.
- Znaki z NN v tabeli od 32 do 127, kodirani z zaporedji od 00100000 do 01111111, so standardni del tabele. Med njimi je prostor (N 32), latinske črke (male in velike črke), desetmestne številke od 0 do 9, ločila, oklepaji različnih vrst in drugi znaki.
- Znaki z zaporednimi številkami od 128 do 255, kodirani s sekvencami od 10.000.000 do 1.000, ki vključujejo črke nacionalnih pisav, ki niso latinske. Ta alternativni del tabele je kodiranje ASCII, ki se uporablja za pretvorbo ruskih znakov v računalniško obliko.
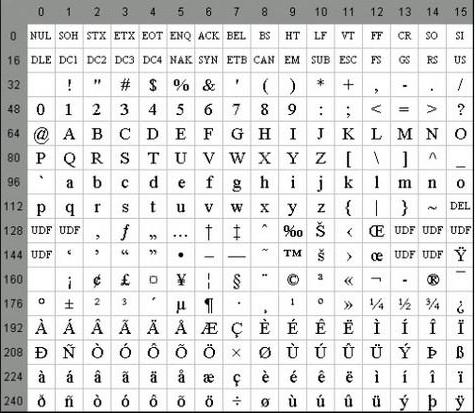
Nekatere lastnosti
Posebnost ASCII kodiranja je razlika med črkama »A« - »Z« spodnjega in zgornjega registra s samo enim bitom. Ta okoliščina močno poenostavlja pretvorbo registra in preverjanje pripadnosti določenemu območju vrednosti. Poleg tega so vse črke v sistemu kodiranja ASCII predstavljene z lastnimi serijskimi številkami v abecedi, ki so zapisane v petih mestih v binarnem številčnem sistemu, pred tem pa za male črke 011 2 , zgornji pa 010 2 .
Ad
Med značilnostmi kodiranja je mogoče prešteti ASCII in predstavitev 10 številk - "0" - "9". V drugem številčnem sistemu se začnejo z 00112 in končajo z dvema številkama. Torej je 0101 2 enakovredno decimalnemu številu pet, tako da je znak "5" zapisan kot 0011 01012. Na podlagi zgoraj navedenega lahko preprosto pretvorite dvojiško-decimalna števila v niz v ASCII z dodajanjem zaporedja bitov 00112 vsakemu grebenu na levo.

"Unicode"
Kot veste, je za prikaz besedil v jezikih skupine jugovzhodne Azije potrebno na tisoče znakov. Takšne številke niso opisane na noben način v enem bajtu informacij, zato tudi razširjene različice ASCII ne morejo več zadostiti naraščajočim potrebam uporabnikov iz različnih držav.
Tako je postalo nujno ustvariti univerzalno kodiranje besedil, katerega razvoj je v sodelovanju s številnimi voditelji globalne IT industrije prevzel konzorcij Unicode. Njeni strokovnjaki so ustvarili sistem UTF 32. V njej je bilo dodeljenih 32 bitov za kodiranje 1 znaka, ki je sestavljal 4 bajtne informacije. Glavna pomanjkljivost je bilo močno povečanje količine potrebnega pomnilnika v kar štirikrat, kar je povzročilo veliko težav.
Ad
Hkrati je za večino držav z uradnimi jeziki, ki pripadajo indoevropski skupini, število znakov, ki je enako 2 32 , več kot pretirano.
Kot rezultat nadaljnjega dela strokovnjakov iz konzorcija Unicode se je pojavilo kodiranje UTF-16. Postala je možnost pretvarjanja simbolnih informacij, ki so bile urejene za vse, tako glede količine zahtevanega spomina kot glede števila kodiranih znakov. Zato je UTF-16 privzeto sprejet in zahteva 2 bajta za en znak.
Tudi ta precej napredna in uspešna različica Unicoda je imela nekaj pomanjkljivosti in po prehodu z razširjene različice ASCII na UTF-16 je podvojila težo dokumenta.
V zvezi s tem je bilo odločeno, da se uporablja kodiranje spremenljive dolžine UTF-8. V tem primeru je vsak znak v izvornem besedilu kodiran v zaporedju od 1 do 6 bajtov.

Obrnite se na ameriško standardno kodo za izmenjavo informacij
Vsi znaki latinico v UTF-8 spremenljivi dolžini, kodirani v 1 bajt, kot v sistemu kodiranja ASCII.
Posebna značilnost UTF-8 je, da v primeru besedila v latinščini brez uporabe drugih znakov, celo programi, ki ne razumejo Unicode, še vedno dovoljujejo branje. Z drugimi besedami, osnovni del kodiranja besedila ASCII se preprosto prenese na novo spremenljivo dolžino UTF. Cirilski znaki v UTF-8 zasedajo 2 bajta, na primer gruzijski - 3 bajti. Z ustvarjanjem UTF-16 in 8 je bila rešena glavna težava pri ustvarjanju enotnega prostora kode v pisavah. Od takrat morajo proizvajalci pisav zapolniti samo tabelo z vektorskimi oblikami besedilnih simbolov, ki temeljijo na njihovih potrebah.
Ad
V različnih operacijskih sistemih imajo prednost različna kodiranja. Za branje in urejanje besedil, natipkanih v drugačnem kodiranju, se uporabljajo ruski programi za pretvorbo besedila. Nekateri urejevalniki besedil vsebujejo vgrajene transkoderje in omogočajo branje besedila ne glede na kodiranje.

Zdaj veste, koliko znakov je v ASCII in kako in zakaj je bil razvit. Seveda je danes standard Unicode postal najbolj razširjen na svetu. Vendar ne smemo pozabiti, da je bila ustvarjena na podlagi ASCII, zato bi morali ceniti prispevek svojih razvijalcev na področju IT.