Tabela znakov Unicode free
Unicode je mednarodni standard za kodiranje znakov, ki vam omogoča, da besedila prikažete enakomerno na katerem koli računalniku na svetu, ne glede na jezik sistema, ki ga uporabljate.
Osnove
Da bi razumeli, zakaj je potrebna tabela simbolov Unicode, najprej preučimo mehanizem za prikaz besedila na zaslonu monitorja. Računalnik, kot vemo, obdeluje vse informacije v digitalni obliki in mora biti prikazan v grafični obliki za pravilno zaznavo osebe. Da bomo lahko prebrali to besedilo, moramo rešiti vsaj dva problema:
- Kodiranje natisljivih znakov v digitalni obliki.
- Operacijskemu sistemu zagotovite možnost, da se digitalna oblika ujema z vektorskimi simboli, z drugimi besedami, poiščite pravilne črke.
Prva kodiranja
Prednik vseh kodiranj se šteje kot ameriški ASCII. Opisal je latinico, ki se uporablja v angleščini ločila in Arabske številke. 128 znakov, uporabljenih v njej, je postalo osnova za nadaljnji razvoj - celo sodobna tabela Unicode simbolov jih uporablja. Črke latinske abecede so od takrat zasedle prvo mesto pri vsakem kodiranju.

Skupno je ASCII dovolil shraniti 256 znakov, vendar je bilo prvih 128 v latinici, preostalih 128 pa se je začelo uporabljati po vsem svetu za oblikovanje nacionalnih standardov. Na primer, v Rusiji so bili na njeni podlagi izdelani CP866 in KOI8-R. Takšne variacije so se imenovale razširjene različice ASCII.
Kode in napake
Nadaljnji razvoj tehnologije in pojav GUI privedlo do dejstva, da je Ameriški inštitut za standardizacijo ustvaril kodiranje ANSI. Za ruske uporabnike, zlasti z izkušnjami, je njegova različica znana kot Windows 1251. V njem je prvič uporabljen koncept »kodna stran«. S pomočjo kodnih strani, ki so vsebovale simbole nacionalnih abeced, razen latinščine, je bilo vzpostavljeno »medsebojno razumevanje« med računalniki, ki se uporabljajo v različnih državah.
Vendar pa je prisotnost velikega števila različnih kodiranj, ki se uporabljajo za en jezik, začela povzročati težave. Bilo je tako imenovanih krakozyabry. Pojavile so se zaradi neusklajenosti izvirne kodne strani, na kateri so bile ustvarjene vse informacije, in kodne strani, ki je bila privzeto uporabljena na računalniku končnega uporabnika.

Kot primer lahko navedemo zgornja kodirana kodiranja CP866 in KOI8-R. Črke v njih so se razlikovale od kodnih položajev in načel postavitve. V prvem so bili razvrščeni po abecednem redu, v drugem pa v poljubnem. Lahko si predstavljate, kaj se je dogajalo pred očmi uporabnika, ki je poskušal odpreti takšno besedilo, ne da bi imel potrebno kodno stran ali če ga je računalnik napačno interpretiral.
Ustvari Unicode
Širjenje interneta in sorodnih tehnologij, kot je elektronska pošta, je privedlo do tega, da je na koncu situacija z izkrivljanjem besedil prenehala ustrezati vsem. Vodilna IT podjetja so ustanovila konzorcij Unicode ("Unicode Consortium"). Tabela znakov, ki jim je bila predstavljena leta 1991 pod imenom UTF-32, je dovolila shranjevanje več kot milijarde edinstvenih znakov. To je bil najpomembnejši korak na poti do dešifriranja besedil.

Vendar pa prva univerzalna tabela znakovnih kod Unicode UTF-32 ni bila široko uporabljena. Glavni razlog je bila redundanca shranjenih podatkov. Hitro je bilo izračunano, da za države, kjer latinico kodirana z novo univerzalno tabelo, bo besedilo trajalo štirikrat več prostora kot pri uporabi razširjene ASCII tabele.
Razvoj Unicode
Naslednja tabela simbolov Unicode UTF-16 je odpravila to težavo. Kodiranje je bilo izvedeno v polovici števila bitov, hkrati pa se je zmanjšalo število možnih kombinacij. Namesto milijarde znakov vam omogoča, da prihranite samo 65.536, kljub temu pa je bila tako uspešna, da je bila ta številka, po odločitvi konzorcija, določena kot osnovni prostor za shranjevanje znakov v standardu Unicode.
Kljub temu uspehu UTF-16 ni ustrezala vsem, saj je bila količina shranjenih in prenesenih informacij še vedno dvakrat višja. Univerzalna rešitev je bila UTF-8, tabela znakov s spremenljivo dolžino Unicode. To lahko imenujemo preboj na tem področju.

Tako je z uvedbo zadnjih dveh standardov tabela simbolov Unicode rešila problem enotnega prostora kode za vse trenutno uporabljene pisave.
Unicode za ruski jezik
Zaradi spremenljive dolžine kode, ki se uporablja za prikaz znakov, je latinica kodirana v Unicode na enak način kot v prediktorju ASCII, to je v enem bitu. Za druge abecede je slika lahko drugačna. Na primer, znaki gruzijske abecede se uporabljajo za kodiranje treh bajtov in znakov cirilice - dva. Vse to je mogoče v okviru uporabe standarda Unicode UTF-8 (tabela simbolov). Ruski jezik ali cirilica zavzema 448 mest v splošnem kodnem prostoru, razdeljenem na pet blokov.
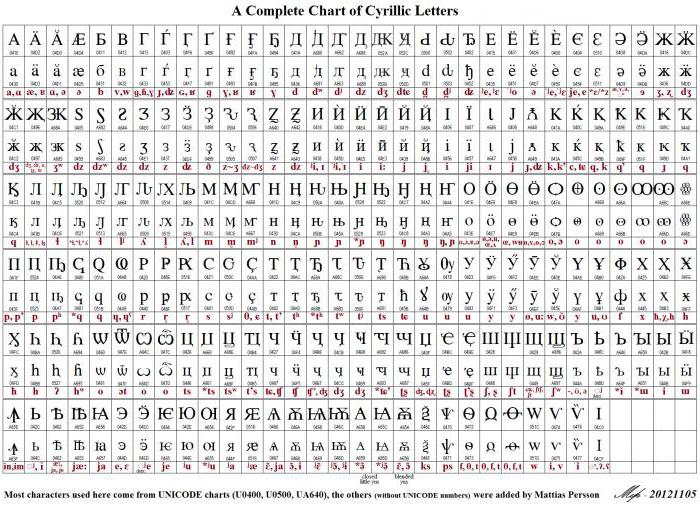
V teh petih blokih sta glavni cirilici in cerkveni slovanski jezik ter dodatne črke drugih jezikov, ki uporabljajo cirilico. Številni položaji so razporejeni tako, da prikažejo stare oblike, ki predstavljajo cirilico, 22 mest od skupnega števila pa ostane prostih.
Trenutna različica Unicode
Z rešitvijo svoje primarne naloge, ki je bila standardizacija pisav in ustvarjanje enotnega kodnega prostora za njih, konzorcij ni ustavil svojega dela. Unicode se nenehno razvija in raste. Zadnja različica tega standarda, 9,0, je bila izdana leta 2016. Vključil je šest dodatnih abeced in razširil seznam standardiziranih čustvenih simbolov.
Treba je opozoriti, da je za poenostavitev raziskav, tudi tako imenovane mrtvi jeziki. To ime so dobili, ker ni ljudi, za katere bi bili sorodniki. V to skupino spadajo tudi jeziki, ki so se zmanjšali le v obliki pisnih spomenikov.
Načeloma lahko vsakdo zaprosi za dodajanje znakov v novo specifikacijo Unicode. Res je, da bo treba zapolniti dostojno količino izvornih dokumentov in porabiti veliko časa. Živi primer tega je zgodba programerja Terencea Edena. Leta 2013 je zaprosil za vključitev v specifikacijo znakov, ki so povezani z označevanjem gumbov za upravljanje moči računalnika. V tehnični dokumentaciji so bili uporabljeni od sredine 70. let prejšnjega stoletja, vendar dokler se ni pojavila specifikacija 9.0, niso bili del Unicode.
Tabela simbolov
Na vsakem računalniku, ne glede na uporabljeni operacijski sistem, se uporablja tabela s simboli Unicode. Kako uporabljati te tabele, kje jih najti in zakaj so lahko uporabne za povprečnega uporabnika?
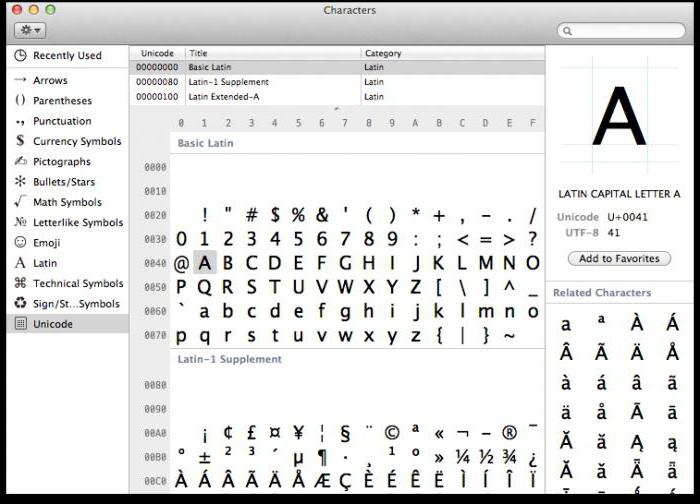
V sistemu Windows se tabela simbolov nahaja v meniju »Orodja«. V družini operacijskih sistemov Linux je običajno mogoče najti v pododdelku »Standard« in v MacOS-u v nastavitvah tipkovnice. Glavni namen te tabele je vnašanje znakov v besedilne dokumente, ki se ne nahajajo na tipkovnici.
Vloga za takšne tabele je najširša: od vnosa tehničnih simbolov in ikon nacionalnih denarnih sistemov do pisanja navodil za praktično uporabo Tarot kart.
Za zaključek
Unicode se uporablja povsod in vstopa v naše življenje skupaj z razvojem interneta in mobilnih tehnologij. Zaradi njegove uporabe je bil sistem medetničnih komunikacij znatno poenostavljen. Lahko rečemo, da je uvedba Unicoda indikativna, vendar povsem neopazna iz primera uporabe tehnologije za skupno dobro vsega človeštva.