Genetski algoritmi: bistvo, opis, primeri, uporaba
Zamisel o genetskih algoritmih (GA) se je pojavila že zdavnaj (1950–1975), vendar so postali pravi predmet študije šele v zadnjih desetletjih. D. Holland je veljal za pionirja na tem področju, ki si je izposodil veliko genetike in ga prilagodil računalnikom. GA se pogosto uporabljajo v sistemih umetne inteligence, nevronskih mrež in optimizacijskih problemih.
Evolucijsko iskanje
Modeli genetskih algoritmov so nastali na podlagi evolucije divjih živali in metod naključnega iskanja. Hkrati pa je naključno iskanje izvedba najenostavnejše evolucijske funkcije - naključne mutacije in poznejša selekcija.
Z matematičnega vidika evolucijsko iskanje ne pomeni nič drugega kot preoblikovanje obstoječe končne množice rešitev v novo. Funkcija, odgovorna za ta proces, je genetsko iskanje. Glavna razlika takšnega algoritma od naključnega iskanja je aktivna uporaba informacij, zbranih med ponovitvami (ponovitvami).
Zakaj potrebujemo genetske algoritme
GA ima naslednje cilje:
- pojasniti mehanizme prilagajanja tako v naravnem okolju kot v intelektualno-raziskovalnem (umetnem) sistemu;
- modeliranje evolucijskih funkcij in njihova uporaba za učinkovito iskanje rešitev različnih problemov, predvsem optimizacijskih.
Trenutno je bistvo genetskih algoritmov in njihovih spremenjenih različic mogoče imenovati iskanje učinkovitih rešitev ob upoštevanju kakovosti rezultata. Z drugimi besedami, najti najboljše razmerje med zmogljivostjo in natančnostjo. To se zgodi zaradi znane paradigme »preživetja najmočnejšega posameznika« v negotovih in nejasnih pogojih.
Značilnosti GA
Najpomembnejše razlike med GA in drugimi metodami iskanja optimalne rešitve so navedene.
- delo s parametri naloge, ki je kodirana na določen način in ne neposredno z njimi;
- iskanje rešitve se ne zgodi z določitvijo začetnega približka, temveč v nizu možnih rešitev;
- uporablja samo ciljno funkcijo, ne da bi se zatekala k njenim izvedenim finančnim instrumentom in spremembam;
- uporaba verjetnostnega pristopa k analizi namesto strogo determinističnega.
Merila uspešnosti
Genetski algoritmi izdelujejo izračune na podlagi dveh pogojev:
- Izvedite določeno število iteracij.
- Kakovost najdene rešitve ustreza zahtevam.
Če je izpolnjen eden od teh pogojev, bo genetski algoritem prenehal izvajati nadaljnje iteracije. Poleg tega jim uporaba GA-jev v različnih regijah prostora rešitev omogoča, da poiščejo boljše nove rešitve, ki imajo primernejše vrednosti ciljne funkcije.
Osnovna terminologija
Ker GA temelji na genetiki, ji večina terminologije ustreza. Vsak genetski algoritem deluje na podlagi začetnih informacij. Niz začetnih vrednosti je populacija t t = {n 1 , n 2 , ..., n n }, kjer je n i = {r 1 , ..., r v }. Podrobneje bomo preučili:
- t je številka ponovitve. t 1 , ..., t k - pomeni ponovitev algoritma od števila 1 do k, pri vsaki ponovitvi pa se ustvari nova populacija rešitev.
- n je velikost populacije P t .
- 1 , ..., п i - хромосома, особь, или организм. n 1 , ..., n i - kromosom, posameznik ali organizem. Kromosom ali veriga je kodirano zaporedje genov, od katerih ima vsaka zaporedno številko. Upoštevati je treba, da je kromosom lahko poseben primer posameznika (organizma).
- r v so geni, ki so del kodirane rešitve.
- Lokus je zaporedna številka gena v kromosomu. Alel je genska vrednost, ki je lahko numerična in funkcionalna.
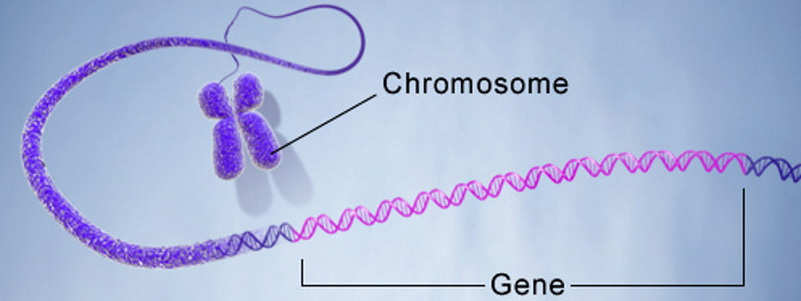
Kaj pomeni "kodirano" v kontekstu GA? Običajno je vsaka vrednost kodirana na podlagi abecede. Najenostavnejši primer je pretvorba številk iz decimalnega števnega sistema v binarno predstavitev. Tako je abeceda predstavljena kot množica {0, 1} in številka 157 10 bo kodirana s kromosomom 10011101 2 , ki ga sestavlja osem genov.
Starši in potomci
Starši so elementi, izbrani v skladu z danim pogojem. Na primer, pogosto je to stanje nesreča. Izbrani elementi zaradi operacij križanja in mutacije povzročajo nove, ki se imenujejo potomci. Tako starši pri izvajanju ene ponovitve genetskega algoritma ustvarjajo novo generacijo.
Končno bo evolucija v tem kontekstu izmenjava generacij, od katerih se vsaka nova odlikuje z nizom kromosomov zaradi boljše telesne pripravljenosti, tj. Ustreznejše skladnosti z določenimi pogoji. Splošno genetsko ozadje v procesu evolucije se imenuje genotip, nastajanje povezave organizma z zunanjim okoljem pa se imenuje fenotip.
Funkcija kondicije
Čarobnost genetskega algoritma v fitnes funkciji. Vsak posameznik ima svojo vrednost, ki jo je mogoče naučiti s funkcijo prilagoditve. Njena glavna naloga je ovrednotiti te vrednosti za različne alternativne rešitve in izbrati najboljšo. Z drugimi besedami, najmočnejši.
Pri optimizacijskih problemih se funkcija fitnesa imenuje tarča, v teoriji nadzora se imenuje napaka, v teoriji iger je funkcija vrednosti in tako naprej. Kaj točno bo predstavljena kot funkcija prilagajanja, je odvisno od problema, ki ga je treba rešiti.
Na koncu lahko sklepamo, da genetski algoritmi analizirajo populacijo posameznikov, organizmov ali kromosomov, od katerih je vsaka predstavljena s kombinacijo genov (številne vrednote), in iščejo optimalno rešitev, pri čemer posameznike spremenijo z umetno evolucijo.
Odstopanja v eni ali drugi smeri posameznih elementov v splošnem primeru so v skladu z običajno zakonodajo porazdelitve količin. Obenem GA zagotavlja dednost lastnosti, od katerih so najbolj prilagojene določene in s tem zagotavljajo najboljšo populacijo.
Osnovni genetski algoritem
V korakih razčlenimo najbolj preprosto (klasično) GA.
- Inicializacija začetnih vrednosti, to je definicija primarne populacije, množica posameznikov, s katerimi bo potekala evolucija.
- Določitev primarne sposobnosti vsakega posameznika v populaciji.
- Preverite pogoje zaključevanja za ponovitve algoritma.
- Uporaba izbirne funkcije.
- Uporaba genetskih operaterjev.
- Ustvarjanje novega prebivalstva.
- Koraki 2-6 se ponavljajo v ciklu, dokler ni izpolnjen potreben pogoj, po katerem pride do izbire najbolj prilagojenega posameznika.
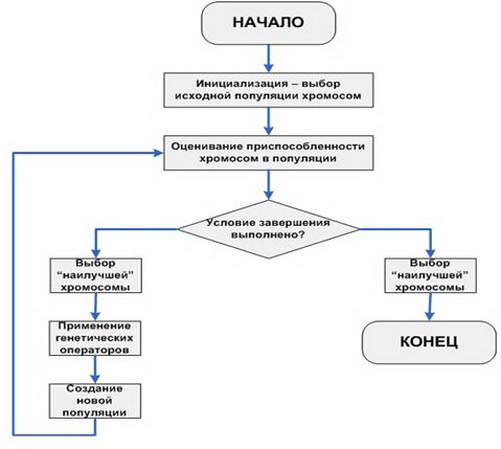
Greva na kratko skozi malo očitne dele algoritma. Obstajata dva pogoja za prekinitev:
- Število ponovitev.
- Kakovost rešitve.
Genetski operaterji so operater mutacije in crossover operater. Mutacija spremeni naključne gene z določeno verjetnostjo. Praviloma ima verjetnost mutacije nizko numerično vrednost. Spregovorimo o postopku genetskega algoritma "križanje". To se dogaja po naslednjem načelu:
- Za vsak par staršev, ki vsebujejo L gene, je naključno izbran prehod Tsk i .
- Prvi naslednik je sestavljen z združevanjem [1; Tsk i ] geni prvega starša [Tsk i + 1 ; L] geni drugega starša.
- Drugi naslednik je sestavljen v obratni smeri. Zdaj geni drugega roditelja [1; Tsk i ] doda gene prvega starša na položaje [Tsk i + 1 ; L].
Trivialni primer
Problem rešujemo z genetskim algoritmom na primeru iskanja posameznika z največjim številom enot. Naj posameznik sestavlja 10 genov. Prvotno populacijo razporejamo v osem oseb. Očitno bi moral biti najboljši posameznik 1111111111. Nadomestimo se odločitve GA.
- Inicializacija. Izberite 8 naključnih posameznikov:
| n 1 | 1110010101 | n 5 | 0101000110 |
| n 2 | 1100111010 | n 6 | 0100110101 |
| n 3 | 1110011110 | n 7 | 0110111011 |
| n 4 | 1011000000 | n 8 | 0100001001 |
- Ocena sposobnosti. Očitno je, da v našem genetskem algoritmu F-funkcija F prešteje število enot v vsakem posamezniku. Tako imamo:
| n i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| F (n i ) | 6 | 7 | 8 | 3 | 4 | 5 | 7 | 3 |
Iz tabele je razvidno, da imajo posamezniki 3 in 7 največje število enot, zato so najbolj primerni člani populacije za rešitev problema. Ker v tem trenutku ni rešitve zahtevane kakovosti, algoritem nadaljuje z delom. Izbrati je treba posameznike. Za lažjo razlago naj bo izbira naključna in dobimo vzorec posameznikov {n 7 , n 3 , n 1 , n 7 , n 3 , n 7 , n 4 , n 2 } - to so starši za novo populacijo.
- Uporaba genetskih operaterjev. Tudi zaradi poenostavitve domnevamo, da je verjetnost mutacij enaka 0. Z drugimi besedami, vseh 8 posameznikov prenaša svoje gene tako, kot so. Če želite prečkati, naredimo pare posameznikov naključno: (n 2 , n 7 ), (n 1 , n 7 ), (n 3 , n 4 ) in (n 3 , n 7 ). Na enak naključni način so izbrani prehodi za vsak par:
| Nekaj | (p 2 , p 7 ) | (n 1 , n 7 ) | (p 3 , p 4 ) | (p 3 , p 7 ) |
| Starši | [1100111010] [0110111011] | [1110010101] [0110111011] | [1110011110] [1011000000] | [1110011110] [0110111011] |
| Tsk i | 3 | 5 | 2 | 8 |
| Potomci | [1100111011] [0110111010] | [1110011011] [0110110101] | [1111000000] [1010011110] | [1110011111] [0110111010] |
- Zbiranje nove populacije, ki jo sestavljajo potomci:
| n 1 | 1100111011 | n 5 | 1111000000 |
| n 2 | 0110111010 | n 6 | 1010011110 |
| n 3 | 1110011011 | n 7 | 1110011111 |
| n 4 | 0110110101 | n 8 | 0110111010 |
- Ocenjujemo primernost vsakega posameznika nove populacije:
| n i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| F (n i ) | 7 | 6 | 7 | 6 | 4 | 6 | 8 | 6 |
Nadaljnji ukrepi so očitni. Najbolj zanimiva stvar pri GA je, če ocenimo povprečno število enot v vsaki populaciji. V prvi populaciji je bilo v povprečju za vsakega posameznika 5.375 enot, v populaciji potomcev - 6,25 enot na posameznika. Takšna značilnost se bo opazila tudi, če se med mutacijami in prečkanjem posameznika z največjim številom enot v prvi populaciji izgubi.
Izvedbeni načrt
Ustvarjanje genetskega algoritma je precej zapletena naloga. Najprej bomo našteli načrt v obliki korakov, po katerem bomo podrobneje preučili vse.
- Opredelitev reprezentacije (abeceda).
- Opredelitev izvajalcev naključnih sprememb.
- Opredelitev preživetja posameznikov.
- Proizvodnja primarne populacije.
Prva stopnja pravi, da mora biti abeceda, v kateri bodo vsi elementi množice rešitev ali populacije kodirani, dovolj prilagodljiva, da omogoči, da se hkrati izvedejo potrebne naključne permutacije in oceni ustreznost elementov, tako primarnih kot tistih, ki so šli skozi spremembe. Matematično je ugotovljeno, da je za te namene nemogoče ustvariti idealno abecedo, zato je njena kompilacija eden najtežjih in najpomembnejših korakov za zagotovitev stabilnega delovanja GA.

Prav tako je težko opredeliti izjave o spremembah in ustvariti potomce. Obstaja veliko operaterjev, ki lahko izvedejo zahtevana dejanja. Na primer, iz biologije je znano, da se lahko vsaka vrsta razmnožuje na dva načina: spolno (s križanjem) in aseksualno (z mutacijami). V prvem primeru starši izmenjujejo genetski material, v drugem pa mutacije, ki jih določajo notranji mehanizmi telesa in zunanji vplivi. Poleg tega se lahko uporabljajo modeli razmnoževanja, ki ne obstajajo v prostoživečih živalih. Na primer, uporabite gene treh ali več staršev. Podobno lahko prehod mutacije v genetski algoritem vključuje različen mehanizem.
Izbira metode preživetja je lahko zelo varljiva. V genetskem algoritmu za vzrejo je veliko načinov. In kot kaže praksa, pravilo "preživetja najmočnejših" ni vedno najboljše. Pri reševanju kompleksnih tehničnih problemov se pogosto izkaže, da je najboljša rešitev iz množice srednjih ali še slabših. Zato je pogosto sprejemljivo, da se uporabi verjetnostni pristop, ki pravi, da ima najboljša rešitev boljše možnosti za preživetje.

Zadnja faza zagotavlja prilagodljivost algoritma, ki ga nihče drug nima. Začetno populacijo rešitev lahko definiramo bodisi na podlagi vseh znanih podatkov bodisi na povsem naključni način, tako da preprosto preuredimo gene znotraj posameznikov in ustvarimo naključne posameznike. Vendar pa se je vedno treba spomniti, da je učinkovitost algoritma odvisna od začetne populacije.
Učinkovitost
Učinkovitost genetskega algoritma je v celoti odvisna od pravilnosti korakov, opisanih v načrtu. Posebej pomemben element je ustvarjanje primarne populacije. Za to obstaja veliko pristopov. Opisali bomo nekaj:
- Ustvarjanje celotnega prebivalstva, ki bo vključevalo vse vrste možnosti za posameznike na določenem območju.
- Naključno ustvarjanje posameznikov na podlagi vseh veljavnih vrednosti.
- Naključno naključno ustvarjanje posameznikov, ko je med sprejemljivimi vrednostmi izbran obseg generacije.
- Združevanje prvih treh načinov za ustvarjanje populacije.

Tako lahko sklepamo, da je učinkovitost genetskih algoritmov v veliki meri odvisna od izkušenj programerja pri tej zadevi. To je hkrati tudi pomanjkljivost genetskih algoritmov in njihova prednost.